
Stable Diffusion杂谈
前言
记录一下扩散模型相关知识和应用,应用主要指文生图模型Stable Diffusion及其生态。
扩散模型相关理论
详细介绍以及数学公式推导见!!!苏剑林的科学空间!!! 张振虎的博客!!!
扩散模型发展至今,有许多可以研究/改进的方向,无论是应用还是算法改进。
如果是偏应用(适配下游任务等)的研究可以仅了解各个关键模型的主要贡献与不足,了解贡献中各个关键词对应公式中的哪部分变量即可。
如果做更底层(优化采样器等)的研究,再去仔细了解各个公式的推导优化过程。
扩散概率模型(diffusion probabilistic model, DPM)
模型信息:DPM,2015。
参考资料:扩散概率模型
关键词:扩散。
提出扩散模型的概念,将热力学中扩散的概念引入深度学习中。
不足:每一步预测的是当前时刻t的图像,预测任务难度大,最终生成图像质量低。
相关资料
早在2015年,就由 Jascha Sohl-Dickstein 和 Eric 等人提出了概率扩散模型(diffusion probabilistic model,DPM),可以简称为扩散模型(diffusion model,DM)。 在原论文中作者表示是受到了非平衡统计物理学(non-equilibrium statistical physics) 的启发进而提出了这个模型。
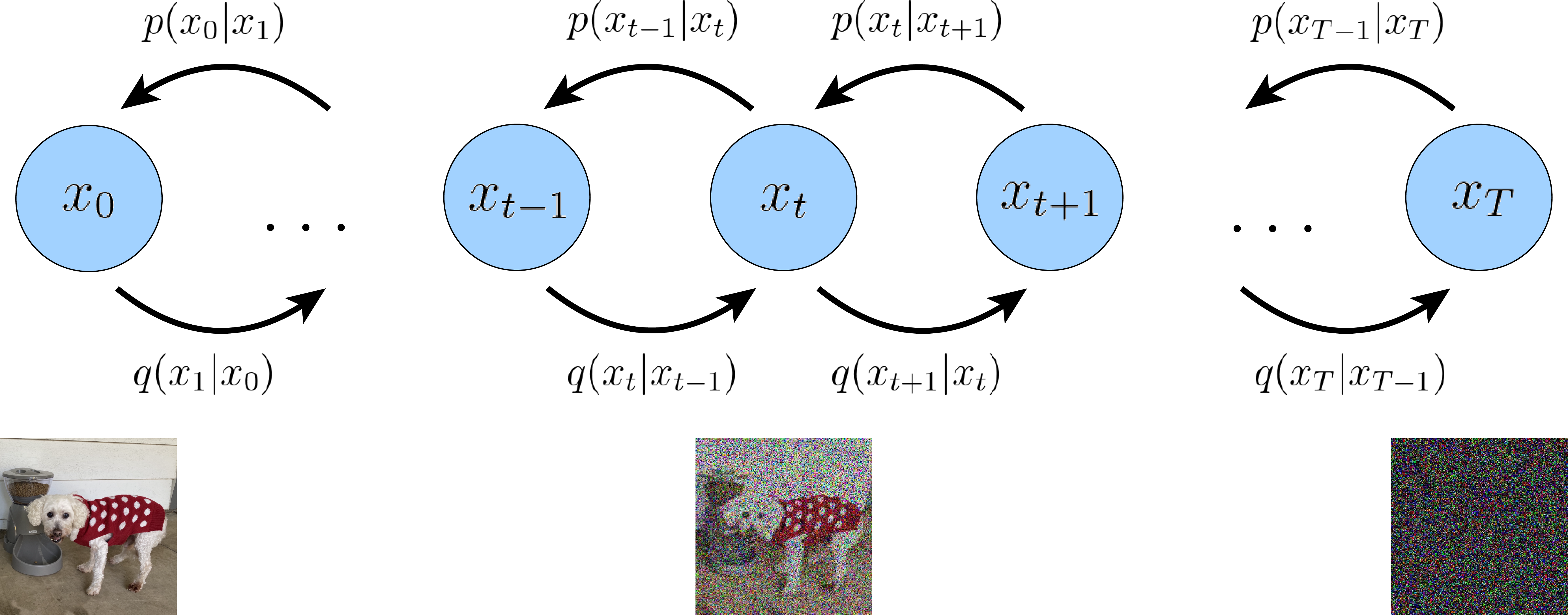
从某个角度上看,扩散模型可以看做是VAE(变分自编码器)的一个扩展,相当于把 VAE 的解码器循环执行了 T 次。 我们把编码过程称为前向过程(Forward Trajectory),解码过程称逆向过程(Reverse Trajectory), 无论前向还是逆向,每一个步骤(时刻) t 仅与它的上一个步骤(时刻)相关, 这是一个典型的马尔科夫过程(Markov chain)。
降噪扩散概率模型(Denoising diffusion probabilistic model, DDPM)
模型信息:DDPM,2020。
参考资料:降噪扩散概率模型; DDPM = 拆楼 + 建楼; DDPM = 自回归式VAE; DDPM = 贝叶斯 + 去噪
关键词:去噪。
与DPM预测t时刻的图像不同,DDPM预测的是t时刻添加的噪声,间接预测图像。预测噪声的难度远低于图像,生成图像质量显著提高。
不足:推理(生成图像)速度慢,通常总步数T为1000,即去噪过程要重复1000次。
相关资料
在 2020年 Ho et al 等人发表了论文 “Denoising Diffusion Probabilistic Models (DDPMs)” ,DDPM 对 DPM 做了关键的改进和优化,解决了 DPM 的一些不足,使得扩散模型生成的图像质量得到了大幅提升, 这才使得扩散模型在图像生成领域大放异彩。 DDPM 做的关键改进就是参数化模型预测的内容做了调整:
- 不再是预测原始的 ,而是预测每一个时刻添加的噪声,降低了模型的学习难度。
去噪扩散隐式模型(Denoising Diffusion Implicit Models,DDIM)
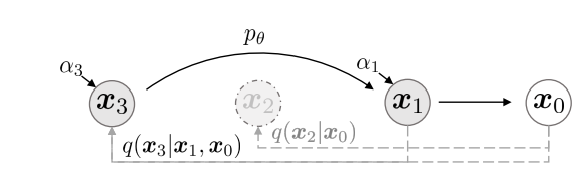
模型信息:DDIM,2022。
参考资料:去噪扩散隐式模型; DDIM = 高观点DDPM
关键词:加速采样。
DDPM基于马尔科夫进行公式推导,得到损失函数;DDIM则从非马尔科夫链形式进行解读与推理,证明采样过程可以直接选择1:T的子序列进行去噪采样。
例如T为1000,选择子序列长度为20,则采样速度加快了50倍。
不足:本渣看不出明显不足。因为是较早的加速采样研究,后续有一些相关的改进工作,但是个人感觉算不上大革新。
相关资料
在 DDPM 中,生成过程被定义为马尔可夫扩散过程的反向过程,在逆向采样过程的每一步,模型预测噪声
DDIM 的作者发现,扩散过程并不是必须遵循马尔科夫链, 在之后的基于分数的扩散模型以及基于随机微分等式的理论都有相同的结论。 基于此,DDIM 的作者重新定义了扩散过程和逆过程,并提出了一种新的采样技巧, 可以大幅减少采样的步骤,极大的提高了图像生成的效率,代价是牺牲了一定的多样性, 图像质量略微下降,但在可接受的范围内。
条件控制生成结果
模型信息:classifier guidance,2021; Classifier-free guidance, 2022。
关键词:可控生成。
通常来说,“文生图模型”中的“文”为图像生成模型的控制条件。CFG在Stable Diffusion中体现为可以设置的反面提示词。
相关资料
从方法上来看,条件控制生成的方式分两种:事后修改(Classifier-Guidance)和事前训练(Classifier-Free)。
对于大多数人来说,一个SOTA级别的扩散模型训练成本太大了,而分类器(Classifier)的训练还能接受,所以就想着直接复用别人训练好的无条件扩散模型,用一个分类器来调整生成过程以实现控制生成,这就是事后修改的Classifier-Guidance方案;而对于“财大气粗”的Google、OpenAI等公司来说,它们不缺数据和算力,所以更倾向于往扩散模型的训练过程中就加入条件信号,达到更好的生成效果,这就是事前训练的Classifier-Free方案。
Classifier-Guidance方案最早出自《Diffusion Models Beat GANs on Image Synthesis》,最初就是用来实现按类生成的;后来《More Control for Free! Image Synthesis with Semantic Diffusion Guidance》推广了“Classifier”的概念,使得它也可以按图、按文来生成。Classifier-Guidance方案的训练成本比较低(熟悉NLP的读者可能还会想起与之很相似的PPLM模型),但是推断成本会高些,而且控制细节上通常没那么到位。
至于Classifier-Free方案,最早出自《Classifier-Free Diffusion Guidance》,后来的DALL·E 2、Imagen等吸引人眼球的模型基本上都是以它为基础做的,值得一提的是,该论文上个月才放到Arxiv上,但事实上去年已经中了NeurIPS 2021。应该说,Classifier-Free方案本身没什么理论上的技巧,它是条件扩散模型最朴素的方案,出现得晚只是因为重新训练扩散模型的成本较大吧,在数据和算力都比较充裕的前提下,Classifier-Free方案变现出了令人惊叹的细节控制能力。
潜在扩散模型(Latent diffusion model,LDM)
模型信息:LDM, 2021
参考资料:潜在扩散模型
关键词:潜在空间,条件处理。
潜在空间。使用VAE的编码器与解码器,对编码后的压缩图像进行各类操作,减小了资源的消耗。
条件处理。使用CLIP 模型中的 text-encoder将文本加工成特征信息,在 UNET 网络中增加 Attention 机制来利用文本特征。
相关资料
DDPM 模型在生成图像质量上效果已经非常好,但它也有个缺点, 那就是 的尺寸是和图片一致的, 的元素和图片的像素是一一对应的, 所以称 DDPM 是像素(pixel)空间的生成模型。 我们知道一张图片的尺寸是 ,如果想生成一张高尺寸的图像, 的张量大小是非常大的,这就需要极大的显卡(硬件)资源,包括计算资源和显存资源。 同样的,它的训练成本也是高昂的。高昂的成本极大的限制了它在民用领用的发展。
2021年德国慕尼黑路德维希-马克西米利安大学计算机视觉和学习研究小组(原海德堡大学计算机视觉小组), 简称 CompVis 小组,发布了论文 High-Resolution Image Synthesis with Latent Diffusion Models,针对这个问题做了一些改进, 主要的改进点有:
- 引入一个自编码器,先对原始对象进行压缩编码,编码后的向量再应用到扩散模型。
- 通过在 UNET 中加入 Attention 机制,处理条件变量 y。
潜在空间
针对 DDPM 消耗资源的问题,解决方法也简单。 引入一个自编码器,比如上一章介绍的变分编码器(VAE),先对原始图像进行压缩编码,得到图像的低维表示 ,然后 作为 DDPM 的输入,执行 DDPM 的算法过程,DDPM 生成的结果再经过解码器还原成图像。 由于 是压缩过的,其尺寸远远小于原始的图像,这样就能极大的减少 DDPM 资源的消耗。 压缩后 所在的数据空间称为潜在空间(latent space), 可以称为潜在数据。
这个自编码器(VAE)可以是提前预训练好的模型,在训练扩散模型时,自编码器的参数是冻住的
- 通过使用预训练的编码器 E,我们可以将全尺寸图像编码为低维潜在空间数据(压缩数据)。
- 通过使用预训练的解码器 D,我们可以将潜在空间数据解码回图像。
这样在 DDPM 外层增加一个 VAE 后,DDPM 的扩散过程和降噪过程都是在潜空间(Latent Space)进行, 潜空间的尺寸远远小于像素空间,极大了降低了硬件资源的需求,同时也能加速整个过程。
正向扩散过程→给潜在数据增加噪声,逆向扩散过程→从潜在数据中消除噪声。 整个 DDPM 的过程都是在潜在空间执行的, 所以这个算法被称为潜在扩散模型(Latent diffusion model,LDM)。 增加一个自编码器并没有改变 DDPM 的算法过程,所以并不需要对 DDPM 算法代码做任何改动。
条件处理
在 DDPM 的过程中,可以增加额外的指导信息,使其生成我们的想要的图像, 比如文本生成图像、图像生成图像等等。
用符号 y 表示额外的条件数据,用 表示 y 的加工处理过程,它负责把 y 加工成特征向量。 比如,如果 y 是一段文本的 prompt, 就是可以是一个 text-encoder, 论文中使用的预训练好的 CLIP 模型中的 text-encoder。 之所以用 CLIP 模型的 text-encoder, 是因为 CLIP 模型本身就是一个文本图像的多模态模型, 它的 text-encoder 能更贴近图像的特征空间, 这里选用一个预训练好的 CLIP 模型即可。
通过在 UNET 网络中增加 Attention 机制把文本的嵌入向量( ) 加入到 UNET 网络中。加入不同的内容可以通过一个开关(switch)来控制。
- 对于文本输入,它们首先使用语言模型 (例如BERT,CLIP)转换为嵌入(向量),然后通过(多头)注意(Q,K,V)层映射到U-Net。
- 对于其他空间对齐的输入(例如语义图、图像、修复),可以使用串联来完成调节。
关于注意力机制的实现细节,可以直接参考论文代码, LDM模型论文的代码和预训练的模型已经在 Github 开源,地址为: https://github.com/CompVis/latent-diffusion 。
Stable Diffusion
LDM 本身是由 CompVis 提出并联合 Runway ML进行开发实现,后来 Stability AI 也参与进来并提供了一些资源, 联合搞了一个预训练的 LDM 模型,称为 Stable diffusion。 所以,Stable diffusion 是 LDM 的一个开源预训练模型,由于它的开源迅速火爆起来。 目前 Stable diffusion 已经占据了图像生成开源领域的主导地位。
Stable Diffusion 是LDM的开源预训练模型。
开源:社区开发者可以参与,所以目前社区生态丰富,各种实际应用项目不断出现。
预训练:有条件可以继续微调。例如各种风格的lora模型,直接使用同种画风或者相同角色的图片继续微调(至过拟合),最终生成类似风格的图片;或者各种ControlNet模型,在UNet模块上增强,引入额外的控制条件,模型更可控。
研究的话通常使用huggingface 开源库 diffusers 中的实现,如果缺少需要的实现则fork代码自行修改,仅应用的话则使用Stable Diffusion web UI。
diffusers 把模型的核心逻辑都封装在各种 DiffusionPipeline 中, StableDiffusionPipeline 核心代码在 diffusers.StableDiffusionPipeline ,看初始化代码,可明显看到整个 StableDiffusionPipeline 包含几个关键组件:vae,text_encoder/tokenizer,unet,scheduler等。 这几个组件和 LDM 中是对应的。
- vae: VAE 自编码器,负责前后的编解码(压缩、解压缩)工作。
- text_encoder/tokenizer: 文本编码器,负责对文本Prompt进行编码处理。
- unet: 噪声预测模型,也是DDPM的核心。
- scheduler: 负责降噪过程(逆过程)的计算,也就是实现 −> ,对应着 DDPM、DDIM、ODE等不同的降采样实现。
SD关键部分即:三个模型组件+1个采样器组件。
研究上,可以针对某一个组件进行强化,相关研究已经有很多:
- 微调强化vae的解码器,生成图片分辨率更高;
- 对unet继续微调,普通形式微调、lora训练画风、ControlNet训练可控生成;
- 一般重新训练模型模型才会改变文本编码器,例如Stable Diffusion v2;
- 继续优化scheduler采样器,提高生成质量或者效率,需要数学基础。
还可以对下游任务进行适配,例如图生图、图像修复等。
图像修复代码示例
进行图生图或图像修复时,可以不去finetune SD模型,只是扩展了它的能力,但是这两样功能就需要精确调整参数才能得到满意的生成效果。 这里给出StableDiffusionInpaintPipelineLegacy这个pipeline内部的核心代码:
1 | import PIL |
风格化finetune模型
SD的另外一大应用是采用特定风格的数据集进行finetune,这使得模型“过拟合”在特定的风格上。之前比较火的novelai就是基于二次元数据在SD上finetune的模型,虽然它失去了生成其它风格图像的能力,但是它在二次元图像的生成效果上比原来的SD要好很多。
目前已经有很多风格化的模型在huggingface上开源,这里也列出一些:
- andite/anything-v4.0:二次元或者动漫风格图像
- dreamlike-art/dreamlike-diffusion-1.0:艺术风格图像
- prompthero/openjourney:mdjrny-v4风格图像
更多的模型可以直接在huggingface text-to-image模型库上找到。此外,很多基于SD进行finetune的模型开源在civitai上,你也可以在这个网站上找到更多风格的模型。 值得说明的一点是,目前finetune SD模型的方法主要有两种:一种是直接finetune了UNet,但是容易过拟合,而且存储成本;另外一种低成本的方法是基于微软的LoRA,LoRA本来是用于finetune语言模型的,但是现在已经可以用来finetune SD模型了,具体可以见博客Using LoRA for Efficient Stable Diffusion Fine-Tuning。
可控生成
可控生成是SD最近比较火的应用,这主要归功于ControlNet,基于ControlNet可以实现对很多种类的可控生成,比如边缘,人体关键点,草图和深度图等等。
其实在ControlNet之前,也有一些可控生成的工作,比如stable-diffusion-2-depth也属于可控生成,但是都没有太火。ControlNet之所以火,是因为这个工作直接实现了各种各种的可控生成,而且训练的ControlNet可以迁移到其它基于SD finetune的模型上(见Transfer Control to Other SD1.X Models)。与ControlNet同期的工作还有腾讯的T2I-Adapter以及阿里的composer-page。
stable-diffusion-webui
最后要介绍的一个比较火的应用stable-diffusion-webui其实是用来支持SD出图的一个web工具,它算是基于gradio框架实现了SD的快速部署,不仅支持SD的最基础的文生图、图生图以及图像inpainting功能,还支持SD的其它拓展功能,很多基于SD的拓展应用可以用插件的方式安装在webui上。
相关资源
huggingface 开源文档: diffusers
 wechat
wechat alipay
alipay




